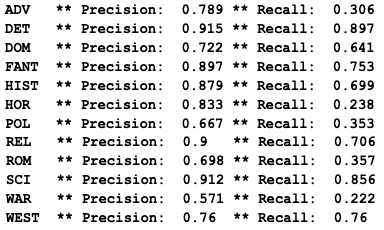
In my previous post, I talked about how we leveraged scikit-learn's classification algorithms for a genre classification problem, and showed that our classifier was substantially more effective at classifying some novel genres than others. You might have noticed that, for the most part, our high-performance genres were “genre fiction” genres: “science fiction,” “fantasy,” and “mystery” are not just literary-historical categories but marketing ones. Publishers use these categories to stabilize demand: readers who have enjoyed science fiction novels in the past will, presumably, purchase additional books marketed under that label in the future. Novels are written with the genre and its rules in mind: the category is a self-conscious one from the point of view of authors, editors, and readers, who intentionally imitate the style of previous works. Domestic fiction, by contrast, is a more ambiguous category. It might be, then, that classification algorithms are better at detecting “genre” in this explicit marketing sense.
One reason for this is that the novels in these genres might themselves be more formulaic or standardized, given that they are designed to meet the demands of an existing readership. Or, at least, they might be more lexically formulaic. Remember that our classifier is basing its decisions only on relative word-frequencies and receives no explicit information about plot, style, grammar, syntax, irony, and so on. Genres like detective fiction and fantasy might simply have more standardized vocabularies than “domestic” fiction. Luckily, scikit-learn lets us access the individual features—in this case, words—that a model uses for classification decisions, which can give us some insight as to the criteria it looks at for each genre.
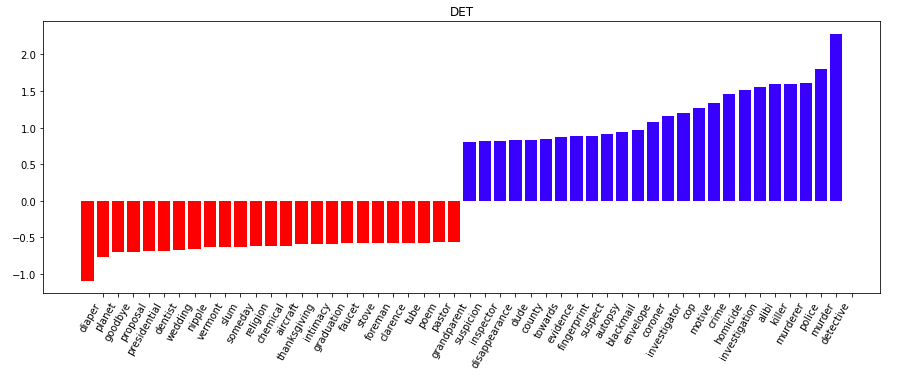 |
| Top 25 positive and negative coefficients for the detective genre |
The results are informative. Top words used for identifying a novel as detective include predictable words like detective, murderer, killer, homicide, and alibi. For fantasy, we see words like wizard, kingdom, and necromancer. Science fiction features words like planet, mars, humanity, and scientist, or, more amusingly, meters and kilometers, which presumably reflects the fact that the metric system sounds exotic and scientific to American readers. Westerns talk about ranches and saloons, while religious fiction includes discussion of repentance, forgiveness, scripture, and jesus (it seems that “religious” mostly means “Protestant Christian,” in this corpus). Romances talk about intimacy, using words like caress and breathlessly. Negative results can be interesting, too: obscenities and sexual language such as shit, breasts, ass, and goddamn are among the top words for identifying a work as not religious fiction.
If we turn to our low-performing genres, however, the lists of top words are more ambiguous and often make less intuitive sense. Domestic fiction has words like wedding, father, grandchild, and birthday, which share a common theme, but also italy and socialism, which are harder to rationalize. This could simply mean that the set of novels that the Library of Congress classes as “domestic fiction” are more lexically heterogeneous than the set labeled “detective” or “fantasy.” Whereas fantasy has unambiguous markers like, say, wizards and elves, domestic fiction is a grab-bag category that can be used to describe any novel that features family or home-life as a central theme. If the texts under a specific label don’t share a consistent vocabulary, then obviously a classifier based on term-frequencies will struggle with them.
Another obstacle for this method was the problem of negative results. In a very early iteration of this project, the classifier assigned no genre at all for more than 2,000 novels. Such a low rate of positives immediately suggested we might have a problem with overfitting, or a classifier that sticks too closely to the training data and thus fails to generalize to new data. Sure enough, when I first opened up the list of features, I was amused to find that the top word for adventure fiction was just the name "Tarzan." I quickly realized that this was due to the corpus itself, which contains more than a dozen of Edgar Rice Borroughs’ original Tarzan novels. The adventure fiction training set was so dominated by these novels that the classifier was unable to find a vocabulary that would generalize to other novels in the class. To a lesser degree, something was also true of religious fiction, which was dominated by the name Winslow because of Gilbert Morris’ House of Winslow series.
One way we mitigated this was by adding in additional genre metadata from Harvard University Library, in order to pad out some of the underrepresented classes. Additionally, we tried classifying on a version of the corpus stripped of all proper names. The intuition here was that character names are almost invariably not generalizable information about a genre. Each new instance of a particular genre features new characters with new names; rather than attempt to find the perfect term-frequency threshold to eliminate proper names, we simply stripped them all. We accomplished this using Spacy’s named-entity recognition (NER) system, which automatically assigns labels to nouns like persons, places, and organizations. Ideally, we would have liked to keep some proper names: Biblical names like “John” and “Paul” actually convey meaningful information about religious fiction, just as the names of historical figures like “Roosevelt” are actually useful for classifying something as a work of historical fiction. Adding more data from Harvard University Library caused the biggest improvement in performance, but stripping names did modestly improve recall for a few classes: religious went up by 6%, for instance, and political by 7%.
 |
| NER for the first line of Charlene Weir’s 1993 novel Consider the Crows |
Despite all this tinkering, the final version of the classifier still left about 900 novels without a genre tag. Many of these are simply novels that don’t fit into any of the categories used by the Library of Congress. Some of them are experimental novels that intentionally evade generic categorization: Michael Chabon’s The Amazing Adventures of Kavalier and Clay; Colson Whitehead’s The Intuitionist; Susan Sontag’s Death Kit; or David Foster Wallace’s Infinite Jest. It’s reasonable enough to argue that the classifier was correct to leave these novels unlabeled. The negative result is an accurate account of the fact that they do not lexically resemble the texts from any of our genre classes.
Still, 8,100 of 9,000 novels is more than enough to make genre-specific corpus searches useful. So for our purposes, machine learning classification has proven effective. In future projects, we may experiment with using similar methods to classify texts in one of our many other corpuses. Most of the other corpuses hosted by the lab are composed of texts much older than the ones in the US Novel Corpus, which means metadata is often even more sparse. This makes the payoff of machine classification potentially greater; however, it introduces additional challenges, since training data may not be readily available.
Jordan Pruett