This is the first of two blog posts describing how we used machine learning classification to produce genre metadata for our US novel corpus, a collection of over 9,000 novels published in the United States between 1880 and 2000. In this first post, I’ll be talking more about the technical side of the project: how we approached the problem, how the classifier works, and how we evaluated its performance. In the second post, I’ll dive a little deeper into what this experiment can teach us about machine learning and text classification in general.
First, a little about the corpus with which we were working. It’s a broad corpus of mostly contemporary American novels, featuring every novel published in the United States between 1880 and 2000 that fulfills two criteria: 1) it is in the holdings of at least two American libraries, as listed in Worldcat, and 2) it is available in a digital format. The corpus was designed as a snapshot of the novels that contemporary librarians think are worth making available to their patrons, which focuses its holdings towards the present.

Like all corpuses at the lab, the US novel corpus is searchable via Philologic, which allows users to search for concordances—shared snippets of text—that appear in multiple works within that corpus. Searches can be restricted by metadata such as author or place of publication. It would be useful to be able to search for concordances by categories that group together texts from multiple authors, such as genre. But here we run into a problem. Unlike publication information, genre metadata is not always readily available, especially for older texts. The information might simply not exist, or might not be reliable. And on a more theoretical level, genre designations lack the rigorous facticity of something like an authorship attribution or a city of publication. Genre is only weakly objective, a structure of family resemblances that is intrinsically more open to nuance and debate than the location of a publishing house. Some texts ride the boundaries of genre, and some readers disagree about genre classifications in the first place.
For these reasons, we decided to treat genre classification as a supervised machine learning problem. Machine learning classification takes family resemblances as its premise: classification algorithms like Multinomial Naive Bayes or a Support Vector Machine (SVM) group observations into categories based on patterns learned from training data. In natural language processing, machine learning classification is commonly used for tasks like email spam filtering. More recently, some scholars have experimented with adopting these classification methods for historical research on literary genres. The most common classification algorithms are all implemented in the open-source Python library scikit-learn, which we used for this project.
Supervised learning requires that you have access to some pre-labeled data that can serve as the algorithm’s training set. For this corpus, we used genre metadata from the Library of Congress, the entire catalog of which is publicly available for download, and Harvard University Library, which makes its catalog available via an API. Previous scholarship on genre classification of novels suggests substantially diminishing returns after a sample size of between 50 and 80. As such, we limited our training data to those genre categories which had at least 50 instances in our corpus. With this method, we were able to pull genre information for ~4,800 of our 9,090 novels. Twelve Library of Congress genre categories passed the threshold, which are listed below along with their counts in the training data.

Classification algorithms require that text data first be converted into a numerical format. For this purpose, we used a simple bag-of-words method with term-frequency, inverse-document-frequency (TF-IDF) weighting. This involves representing each text as a long vector composed of scores for every word that appears in any of the 9,090 novels in the corpus. A novel’s score for each word increases proportionally to the number of times that word appears in that novel, offset by the total number of novels in the corpus that contain that word. Thus, words that appear in many novels are down-weighted, which is important, since especially common words will not be “distinctive” and so will be less useful for classification. Finally, we limited our vocabulary to only the top 20,000 terms by document frequency. Any higher proved superfluous in testing, which makes sense considering that the average adult speaker of English only has an active vocabulary of 20,000 words.
Genres are not exclusive categories; a novel can have one, several, or even zero genres, if its genre is not one of the twelve genres we selected for this problem. In machine learning parlance, this means that genre categorization is a multilabel classification problem. For each text, the classifier will assign a positive or negative result for each of the twelve genres. Under the hood, the classifier is actually just training 12 different classifiers, one for each genre, and repeating the experiment 12 times. An unfortunate side effect of this method is that some of the genres which were poorly-represented by the training data received very few positive results. Likewise, about 900 of the 9000 texts received zero genre designations at all. This problem cannot be avoided without a cost to the precision of the classifier. But we decided that accurate results for the majority of our texts would be more useful to users than dubious results for all of them.

In testing, we tried four of the most popular algorithms for text classification: multinomial naive Bayes, regularized logistic regression, K-nearest neighbors, and a linear support vector machine (SVM). Linear SVM consistently performed the best, with logistic regression coming in a close second place. This result was largely expected. Linear SVM is known to work especially well for text classification, because it is well-suited for tasks involving sparse vectors, or vectors with many 0 values. Document vectors are usually sparse, since any one document will contain a comparatively small number of all the words contained in the total vocabulary of the corpus.
Just how well did it perform? We cross-validated by repeating the experiment five times and shuffling the training and the testing data each time. In each version of the experiment, 80% of the texts served as training data and 20% of the texts served as test data. The Linear SVM classifier achieved an average precision score of about 80%, with a margin of error of 4%. That’s pretty good! That means that about 80% of the positive results assigned by the classifier were correct results. For recall, the score averaged 72%, with a much larger margin of error of 16%. This lower recall score means that there are a fair number of false negatives, or genre designations that the classifier fails to pick up on. In any classification problem, precision and recall involve a trade-off. For this task, we decided that an incorrect negative result is more acceptable than an incorrect positive result: we care more whether something is incorrectly labeled “detective” than if it is incorrectly labeled “not detective.”
Let’s delve into these results a little deeper and see where the classifier performs well and where it struggles. Does it do better with some genres than with others? Since the classifier is really just a series of binary classifiers, we can easily get performance metrics for each genre label. Here we can clearly see that the classifier seems to struggle with a few genres. Horror, war, and political fiction each have relatively low recall scores, which means that the classifier gives them negative results when they should be positive. A bias towards negative results for these particular classes isn’t a huge problem, since we know they appear relatively few times in the corpus. The classifier will be technically right most of the time if it simply says “no” to these classes whenever it’s asked about them.
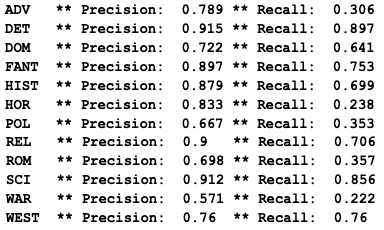
But for a few genres, the classifier achieved really remarkable results. For detective and mystery fiction, its precision score is 91%; for science fiction, 91%; for religious, 90%; and for fantasy, 89%. Why do we see such a dramatic difference in quality in these different genres? Part of the issue has to do with unbalanced classes: the training data includes almost two thousand detective novels but only 72 war stories. The classifier will inevitably perform better at classifying the genres for which it has seen the most examples. But this doesn’t fully explain the divergence; we have more cases of “domestic” than “religious,” but the classifier does worse with the former than the latter. In my next blog post, I’ll delve into the question of why some genres are easier to classify by this method than others, and what this teaches us about both machine learning and literary history.
Read Part Two Here
Jordan Pruett
Harika bir yazı olmuş, emeğinize sağlık.
ReplyDeleteBilgi dolu bir içerik olmuş, devamını beklerim.
ReplyDeleteModern fleet of cranes for all needs. crane lifting attachments
ReplyDelete